Introduction: CSV (Comma-Separated Values) files are a popular format for storing tabular data, commonly used in data processing, analysis, and exchange due to their simplicity and compatibility with a wide range of software applications. Working with CSV files in Python provides developers with powerful tools and libraries for reading, writing, and manipulating tabular data efficiently. In this comprehensive guide, we will explore the principles, methods, and best practices for working with CSV files in Python, empowering developers to harness the full potential of tabular data processing.
- Understanding CSV Files: CSV files are plain-text files that store tabular data in a structured format, with rows representing individual records and columns representing fields or attributes. Each field within a row is separated by a delimiter, commonly a comma, semicolon, or tab character. CSV files are widely used for storing data exported from spreadsheets, databases, and other software applications, making them a versatile and ubiquitous format for data exchange and analysis.
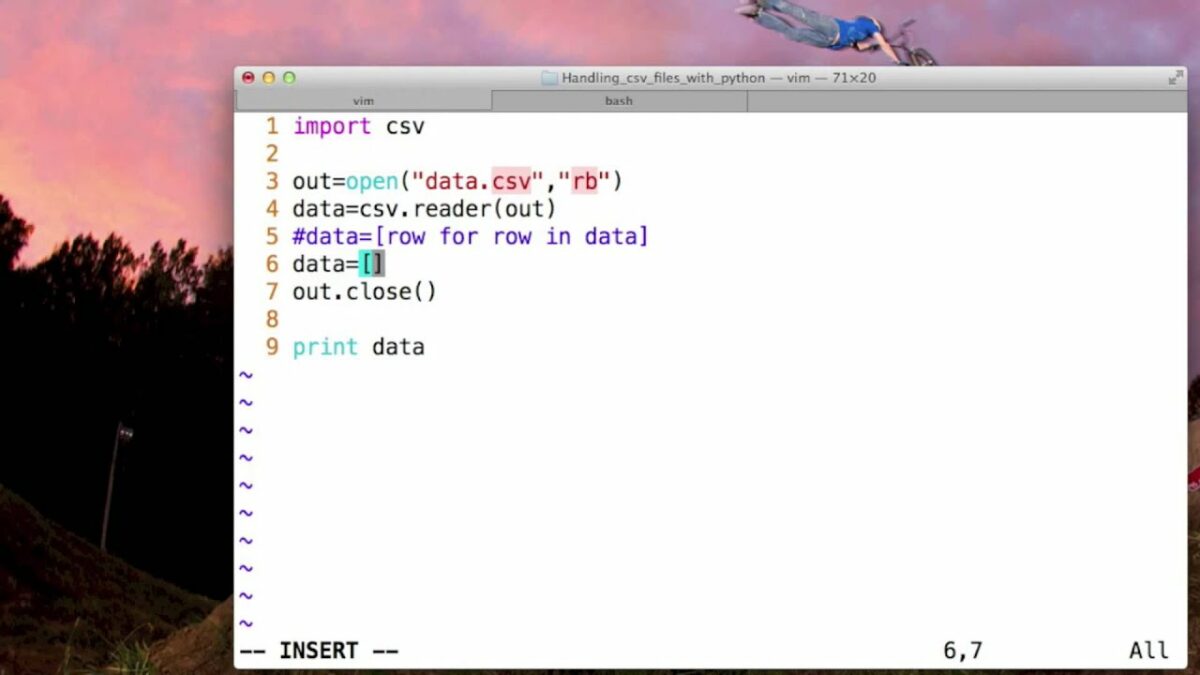
- Reading CSV Files: Python provides built-in and third-party libraries for reading CSV files, making it easy to parse and extract data from CSV files into Python data structures such as lists, dictionaries, or pandas DataFrames. The built-in
csvmodule in Python offers a simple and efficient way to read CSV files, with functions such ascsv.reader()andcsv.DictReader()for reading rows as lists or dictionaries, respectively. Additionally, libraries like pandas provide high-level functions for reading CSV files directly into DataFrames, enabling powerful data manipulation and analysis. - Writing CSV Files: Python also offers robust support for writing data to CSV files, allowing developers to create, modify, and export tabular data in CSV format. The
csvmodule provides functions such ascsv.writer()andcsv.DictWriter()for writing data to CSV files, with options for specifying delimiters, quoting rules, and newline characters. Libraries like pandas offer convenient methods for exporting DataFrames to CSV files, preserving column names and data types while providing flexibility in formatting and customization. - Parsing CSV Data: When working with CSV files in Python, it is essential to parse and preprocess the data appropriately to handle edge cases, missing values, and data inconsistencies. Techniques such as data validation, type conversion, and error handling can be applied to ensure data integrity and reliability. Python’s rich ecosystem of data manipulation libraries, including NumPy, pandas, and scikit-learn, provides powerful tools for cleaning, transforming, and analyzing CSV data efficiently.
- Handling Headers and Data Structures: CSV files often include headers that specify column names or field labels, making it easier to interpret and manipulate the data. Python libraries for CSV handling typically support options for reading and writing headers, allowing developers to customize the handling of header rows. Additionally, CSV files may contain nested or hierarchical data structures, such as multi-level headers or nested records, which require special handling and processing techniques to extract and represent accurately in Python data structures.
- Dealing with Delimiters and Quoting: CSV files support various delimiters and quoting conventions to accommodate different data formats and special characters. Python’s
csvmodule provides options for specifying custom delimiters, quoting characters, and escape characters when reading or writing CSV files, allowing developers to handle edge cases and non-standard formats gracefully. Additionally, libraries like pandas offer robust support for detecting and handling quoting and escaping automatically during data import and export operations. - Working with Large CSV Files: Handling large CSV files efficiently is a common challenge in data processing and analysis tasks, requiring strategies for memory management, streaming, and parallel processing. Python libraries such as pandas offer optimizations for reading and processing large CSV files in chunks or batches, allowing developers to work with data sets that exceed available memory capacity. Additionally, techniques such as multi-threading, multiprocessing, or distributed computing can be employed to parallelize data processing tasks and improve performance.
- Data Manipulation and Analysis: Once CSV data is imported into Python, developers can leverage the rich ecosystem of data manipulation and analysis libraries to perform a wide range of tasks, including filtering, sorting, aggregating, grouping, and visualizing data. Libraries like pandas provide powerful functions and methods for performing complex data transformations, statistical analysis, and exploratory data visualization, enabling insights and discoveries from tabular data sets.
- Error Handling and Data Validation: When working with CSV files in Python, it is crucial to implement robust error handling and data validation mechanisms to detect and handle issues such as missing values, invalid data types, or data integrity errors. Python’s exception handling mechanisms, along with libraries for data validation and schema enforcement, provide tools for detecting and resolving errors during CSV parsing, preprocessing, and analysis.
- Best Practices and Tips: To maximize efficiency and maintainability when working with CSV files in Python, developers should adhere to best practices and follow established conventions for file handling, data processing, and code organization. Some best practices include modularizing code into reusable functions or classes, documenting data processing pipelines, using meaningful variable names and comments, and testing code thoroughly to ensure correctness and reliability.
Conclusion: Working with CSV files in Python provides developers with powerful tools and libraries for parsing, processing, and analyzing tabular data efficiently. By understanding the principles, methods, and best practices for handling CSV files, developers can unlock the full potential of tabular data processing and analysis in Python, enabling insights, discoveries, and actionable intelligence from diverse data sets. Whether working with small-scale data sets or large-scale data pipelines, Python’s rich ecosystem of libraries and tools offers versatile solutions for tackling a wide range of data challenges with confidence and efficiency.